Cross-Cloud Access: A Native Kubernetes OIDC Approach
Written in collaboration with Chloe Blain
Goal
Setup a minimal working example where pods in GKE and EKS can access two buckets, one in S3 and another in GCS with no static credentials or runtime configuration. In other words, running the below commands should just work from within a pod in both clusters:
$ aws s3 ls s3://oidc-exp-s3-bucket
$ gcloud storage ls gs://oidc-exp-gcs-bucket
Context
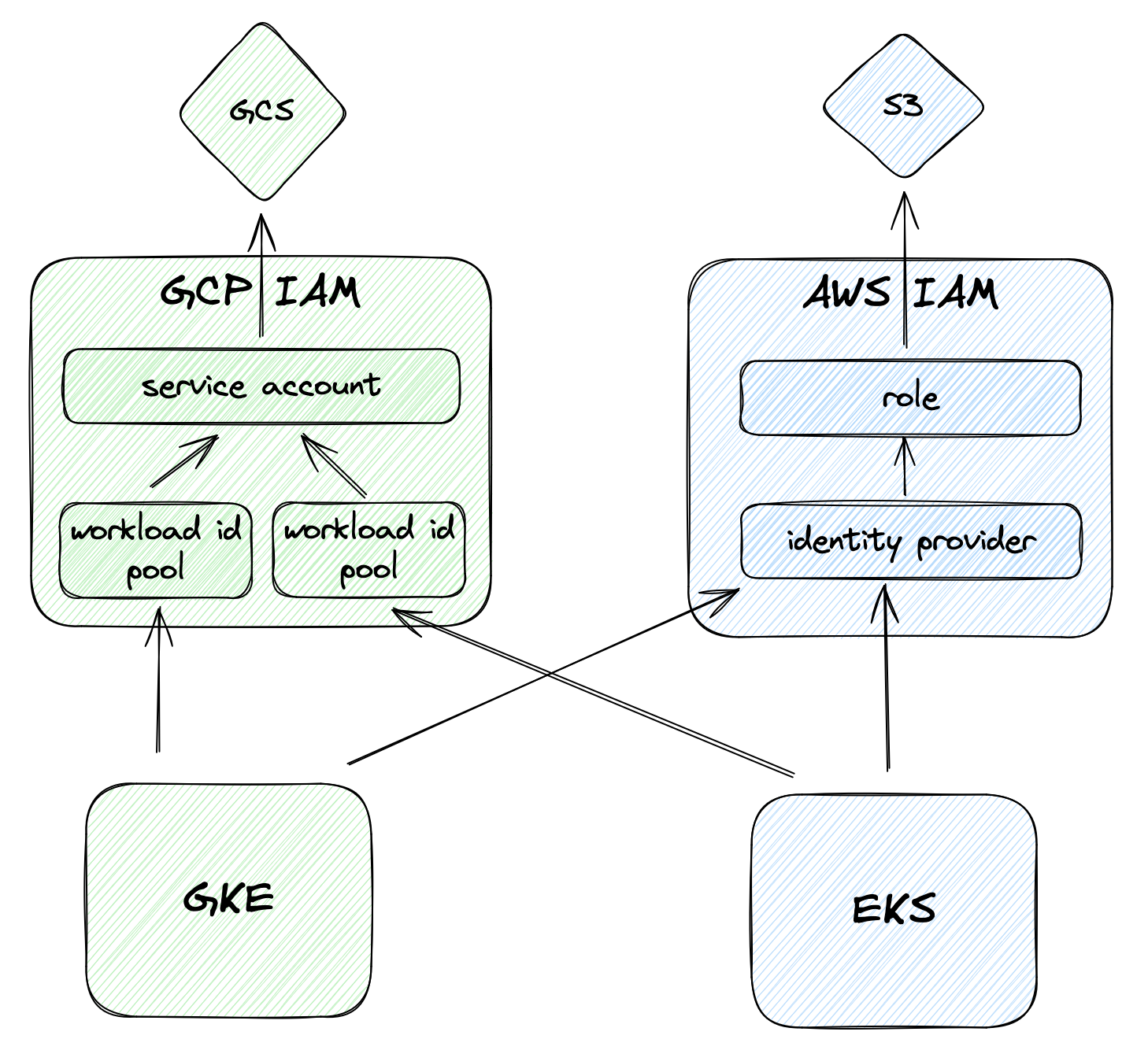
Communicating with Cloud APIs without the use of static, long-lived credentials from within Kubernetes requires some work even when using the CSP’s managed Kubernetes versions. In AWS, this is done through EKS Pod Identities, or IAM Roles for Service Accounts (IRSA), while in GCP this is achieved through Workload Identity Federation (WIF) for GKE.
Both IRSA and Workload Identity Federation leverage OpenID Connect (OIDC) with Kubernetes configured as an Identity Provider on both clouds’ IAM to assume roles (AWS) and impersonate service accounts (GCP). The two processes are well documented online.
However, when a Kubernetes workload running in one CSP needs to access services in another CSP, the configuration might not be as straightforward and potentially have more than way of achieving the desired result.
In particular, the path from GKE to AWS APIs is not as well documented when trying to use Kubernetes itself as the Identity Provider to AWS IAM. Both AWS’s recent blog post on the topic and the doitintl/gtoken project rely on Google (not Kubernetes) being the Identity Provider and the execution of some pre-steps or configuration of Mutating Webhooks to get workloads to “just work”.
However, it is possible to achieve keyless cross-cloud access using Kubernetes OIDC as the Identity Provider for both EKS and GKE. While there’s a good amount of pre-configuration involved, the result is very flexible and fully native. This post will demonstrate how to do so.
If you’re unfamiliar with the OIDC Authentication flow, here’s one way to think about it in simple terms:
- The Cluster Administrator configures the Kubernetes Cluster and its access is secure and controlled.
- Kubernetes provides ServiceAccounts with an identity token that has been signed with a private key.
- The Cluster Administrator reviews the Pod and ServiceAccount creations and modifications or trusts others to do so.
- CSPs can be configured to accept IAM requests that come from clusters, by verifying their signature and identity - this is possible because they’ve been previously configured with the public key of the cluster.
- Pods use the ServiceAccount token to authenticate with the CSP IAM and exchange them for short lived credentials that have access to other APIs.
Real World Example
A fully working IaC example is available on https://github.com/arturhoo/oidc-exp/ - below the main points are demonstrated. The examples start from the in-cloud access and then move to cross-cloud access.
For this exercise, two buckets will be created with a text file, one on each CSP.
resource "aws_s3_bucket" "s3_bucket" {
bucket = var.s3_bucket
}
resource "aws_s3_object" "s3_object" {
bucket = aws_s3_bucket.s3_bucket.id
key = "test.txt"
content = "Hello, from S3!"
}
resource "google_storage_bucket" "gcs_bucket" {
name = var.gcs_bucket
location = var.gcp_region
}
resource "google_storage_bucket_object" "gcs_object" {
bucket = google_storage_bucket.gcs_bucket.name
name = "test.txt"
content = "Hello, from GCS!"
}
EKS to AWS
To access AWS APIs from workloads in EKS there are primarily two options: EKS Pod Identities, or IAM Roles for Service Accounts (IRSA). Here the focus is on IRSA since the exercise focuses on Kubernetes OIDC.
All EKS clusters (including those with only private subnets and private endpoints) have a publicly available OIDC discovery endpoint, that allows other parties to verify the signature of potential JWT tokens (exposed in the URL under jwks_uri) that have been allegedly signed by the cluster.
$ xh https://oidc.eks.eu-west-2.amazonaws.com/id/4E604436464FFCC52F8B96807F5BD5BC/.well-known/openid-configuration
{
"issuer": "https://oidc.eks.eu-west-2.amazonaws.com/id/4E604436464FFCC52F8B96807F5BD5BC",
"jwks_uri": "https://oidc.eks.eu-west-2.amazonaws.com/id/4E604436464FFCC52F8B96807F5BD5BC/keys",
"authorization_endpoint": "urn:kubernetes:programmatic_authorization",
"response_types_supported": [
"id_token"
],
"subject_types_supported": [
"public"
],
"claims_supported": [
"sub",
"iss"
],
"id_token_signing_alg_values_supported": [
"RS256"
]
}
The first step is configuring the EKS cluster to be an Identity Provider in AWS IAM:
data "tls_certificate" "cert" {
url = aws_eks_cluster.primary.identity[0].oidc[0].issuer
}
resource "aws_iam_openid_connect_provider" "oidc_provider" {
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = [data.tls_certificate.cert.certificates[0].sha1_fingerprint]
url = aws_eks_cluster.primary.identity[0].oidc[0].issuer
}
Then, a role that can read from S3 must be created. This role will have an AssumeRole policy that uses the previously configured EKS cluster as a federated identity provider. To make it more restrictive, we define a condition on the sub claim of the JWT token signed by the cluster to match the namespace and service account the workload itself will use.
resource "aws_iam_role" "federated_role" {
name = "oidc_exp_federated_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
"Effect" : "Allow",
"Principal" : {
"Federated" : aws_iam_openid_connect_provider.oidc_provider.arn
},
"Action" : "sts:AssumeRoleWithWebIdentity",
"Condition" : {
"StringEquals" : {
"${local.eks_issuer}:aud" : "sts.amazonaws.com",
"${local.eks_issuer}:sub" : "system:serviceaccount:default:oidc-exp-service-account"
}
}
}
]
})
}
resource "aws_iam_policy" "s3_read_policy" {
name = "s3_read_policy"
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Action = ["s3:GetObject", "s3:GetObjectVersion", "s3:ListBucket"],
Resource = [
"arn:aws:s3:::${var.s3_bucket}",
"arn:aws:s3:::${var.s3_bucket}/*",
],
},
],
})
}
resource "aws_iam_role_policy_attachment" "s3_read_policy_attachment" {
role = aws_iam_role.federated_role.name
policy_arn = aws_iam_policy.s3_read_policy.arn
}
Finally, on EKS, a service account with a specific annotation is needed:
apiVersion: v1
kind: ServiceAccount
metadata:
name: oidc-exp-service-account
namespace: default
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::$AWS_ACCOUNT_ID:role/oidc_exp_federated_role
apiVersion: v1
kind: Pod
metadata:
name: aws-cli
namespace: default
spec:
containers:
- name: aws-cli
image: amazon/aws-cli
command:
- /bin/bash
- -c
- "sleep 1800"
serviceAccountName: oidc-exp-service-account
Behind the scenes, EKS is using a Mutating Webhook Controller to mount an OIDC token signed by the cluster into the pod through a volume projection and setting an environment variable for AWS_WEB_IDENTITY_TOKEN_FILE and AWS_ROLE_ARN, which in turn are used by the AWS SDK as auto configuration. We can see the modifications made to the pod there weren’t originally present in the pod definition above:
$ kubectl --context aws get pod aws-cli -o yaml
apiVersion: v1
kind: Pod
metadata:
name: aws-cli
namespace: default
...
spec:
...
env:
- name: AWS_STS_REGIONAL_ENDPOINTS
value: regional
- name: AWS_DEFAULT_REGION
value: eu-west-2
- name: AWS_REGION
value: eu-west-2
- name: AWS_ROLE_ARN
value: arn:aws:iam::<REDACTED>:role/oidc_exp_federated_role
- name: AWS_WEB_IDENTITY_TOKEN_FILE
value: /var/run/secrets/eks.amazonaws.com/serviceaccount/token
image: amazon/aws-cli
...
name: aws-cli
volumeMounts:
- mountPath: /var/run/secrets/eks.amazonaws.com/serviceaccount
name: aws-iam-token
readOnly: true
...
...
volumes:
- name: aws-iam-token
projected:
defaultMode: 420
sources:
- serviceAccountToken:
audience: sts.amazonaws.com
expirationSeconds: 86400
path: token
...
...
status:
...
phase: Running
This allows reads from S3 without any other changes from within the pod:
$ kubectl --context aws exec -it gcloud-cli -- bash
bash-4.2# aws s3 ls s3://oidc-exp-s3-bucket
2024-03-17 18:29:42 15 test.txt
Success! 1/4 complete.
GKE to GCP
As previously mentioned, the golden path is through Workload Identity Federation (WIF) for GKE. When Workload Identity is Enabled for a GKE cluster, an implicit Workload Identity Pool is created with the format PROJECT_ID.svc.id.goog, and the GKE Issuer URL configured behind the scenes.
resource "google_container_cluster" "primary" {
...
workload_identity_config {
workload_pool = "${data.google_project.project.project_id}.svc.id.goog"
}
}
We will also need a GCP IAM Service account with the correct permissions to read from the bucket:
resource "google_service_account" "default" {
account_id = "oidc-exp-service-account"
display_name = "OIDC Exp Service Account"
}
resource "google_storage_bucket_iam_binding" "viewer" {
bucket = var.gcs_bucket
role = "roles/storage.objectViewer"
members = ["serviceAccount:${google_service_account.default.email}"]
}
In Kubernetes, a Service Account must be created with a special annotation that will allow the GCP SDK to perform a multi-step process that intercept calls to GCP APIs and exchanges a service account token generated on-demand by the cluster for a GCP access token, which is then used to access the APIs. For this reason, contrary to EKS, no service account volume projection takes place.
apiVersion: v1
kind: ServiceAccount
metadata:
name: oidc-exp-service-account
namespace: default
annotations:
iam.gke.io/gcp-service-account: oidc-exp-service-account@$GCP_PROJECT_ID.iam.gserviceaccount.com
For the previously mentioned token exchange to take place, the GCP IAM Service Account must have the federated K8s service account configured to assume it:
resource "google_service_account_iam_binding" "service_account_iam_binding" {
service_account_id = google_service_account.default.name
role = "roles/iam.workloadIdentityUser"
members = [
"serviceAccount:${var.gcp_project_id}.svc.id.goog[default/oidc-exp-service-account]",
]
}
The pod simply uses the service account:
apiVersion: v1
kind: Pod
metadata:
name: gcloud-cli
namespace: default
spec:
containers:
- name: gcloud-cli
image: gcr.io/google.com/cloudsdktool/google-cloud-cli:alpine
command:
- /bin/bash
- -c
- "sleep 1800"
serviceAccountName: oidc-exp-service-account
With the pod online, we can test our GCS access:
$ kubectl --context gke exec -it gcloud-cli -- bash
gcloud-cli:/# gcloud storage ls gs://oidc-exp-gcs-bucket
gs://oidc-exp-gcs-bucket/test.txt
Success! 2/4 complete.
GKE to AWS
Things become interesting now! As previously mentioned, most of the documentation available online is about Google, not Kubernetes (GKE), being the Identity Provider. However, the GKE cluster itself can be used as the Identity Provider, like how EKS was used in the EKS to AWS section.
The first step is to configure the GKE cluster as an Identity Provider in AWS IAM:
locals {
gke_issuer_url = "container.googleapis.com/v1/projects/${var.gcp_project_id}/locations/${var.gcp_zone}/clusters/oidc-exp-cluster"
}
resource "aws_iam_openid_connect_provider" "trusted_gke_cluster" {
url = "https://${local.gke_issuer_url}"
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = ["08745487e891c19e3078c1f2a07e452950ef36f6"]
}
Similar to AWS, all GKE clusters also has a publicly available OIDC discovery endpoint:
$ xh https://container.googleapis.com/v1/projects/$GCP_PROJECT_ID/locations/$GCP_ZONE/clusters/oidc-exp-cluster/.well-known/openid-configuration
{
"issuer": "https://container.googleapis.com/v1/projects/$GCP_PROJECT_ID/locations/$GCP_ZONE/clusters/oidc-exp-cluster",
"jwks_uri": "https://container.googleapis.com/v1/projects/$GCP_PROJECT_ID/locations/$GCP_ZONE/clusters/oidc-exp-cluster/jwks",
"response_types_supported": [
"id_token"
],
"subject_types_supported": [
"public"
],
"id_token_signing_alg_values_supported": [
"RS256"
],
"claims_supported": [
"iss",
"sub",
"kubernetes.io"
],
"grant_types": [
"urn:kubernetes:grant_type:programmatic_authorization"
]
}
We will want to assume the same role that the pod in EKS assumed, therefore, we just need to update the AssumeRole policy to include the following statement:
{
"Effect" : "Allow",
"Principal" : {
"Federated" : aws_iam_openid_connect_provider.trusted_gke_cluster.arn
},
"Action" : "sts:AssumeRoleWithWebIdentity",
"Condition" : {
"StringEquals" : {
"${local.gke_issuer_url}:sub" : "system:serviceaccount:default:oidc-exp-service-account",
}
}
},
At this point, the IAM has been configured and all that is left is configure the Pod appropriately. While we could install the Mutating Webhook Controller that AWS uses, it is also trivial to setup the service account volume projection and define the expected variables for AWS SDK to auto configuration:
apiVersion: v1
kind: Pod
metadata:
name: aws-cli
namespace: default
spec:
containers:
- name: aws-cli
image: amazon/aws-cli
command:
- /bin/bash
- -c
- "sleep 1800"
volumeMounts:
- mountPath: /var/run/secrets/tokens
name: oidc-exp-service-account-token
env:
- name: AWS_WEB_IDENTITY_TOKEN_FILE
value: "/var/run/secrets/tokens/oidc-exp-service-account-token"
- name: AWS_ROLE_ARN
value: "arn:aws:iam::$AWS_ACCOUNT_ID:role/oidc_exp_federated_role"
serviceAccountName: oidc-exp-service-account
volumes:
- name: oidc-exp-service-account-token
projected:
sources:
- serviceAccountToken:
path: oidc-exp-service-account-token
expirationSeconds: 86400
audience: sts.amazonaws.com
Here’s a sample decoded JWT token that is mounted on the pod and sent to AWS IAM, which will verify the signature and claims previously configured:
{
"aud": [
"sts.amazonaws.com"
],
"exp": 1710979065,
"iat": 1710892665,
"iss": "https://container.googleapis.com/v1/projects/$GCP_PROJECT_ID/locations/$GCP_ZONE/clusters/oidc-exp-cluster",
"kubernetes.io": {
"namespace": "default",
"pod": {
"name": "aws-cli",
"uid": "bcf6d914-7ce5-4332-a417-510b3cbc144a"
},
"serviceaccount": {
"name": "oidc-exp-service-account",
"uid": "c56d2a4c-2622-41e1-8c7e-e3ab6eba39b5"
}
},
"nbf": 1710892665,
"sub": "system:serviceaccount:default:oidc-exp-service-account"
}
At this point the pod is ready to be launched and the S3 bucket can be listed without any further configuration:
$ kubectl --context gke exec -it aws-cli -- bash
bash-4.2# aws s3 ls s3://oidc-exp-s3-bucket
2024-03-17 18:29:42 15 test.txt
Success! 3/4 complete.
EKS to GCP
The final configuration is from EKS to GCP. While GKE clusters are configured as OIDC providers in the project-default Workload Identity Pool, we can’t add custom providers there. Therefore, we need to create a new pool:
locals {
workload_identity_pool_id = "oidc-exp-workload-identity-pool"
}
resource "google_iam_workload_identity_pool" "pool" {
workload_identity_pool_id = local.workload_identity_pool_id
}
Then, we need to add the EKS cluster as a provider. Note that we’re using the same OIDC issuer URL as we did in the EKS to AWS section.
resource "google_iam_workload_identity_pool_provider" "trusted_eks_cluster" {
workload_identity_pool_id = google_iam_workload_identity_pool.pool.workload_identity_pool_id
workload_identity_pool_provider_id = "trusted-eks-cluster"
attribute_mapping = {
"google.subject" = "assertion.sub"
}
oidc {
issuer_uri = aws_eks_cluster.primary.identity[0].oidc[0].issuer
}
}
Finally, we want the pods in EKS to be able to impersonate the GCP IAM Service Account we previously created for the GKE to GCP path. Therefore, we add a new member to the existing policy binding:
resource "google_service_account_iam_binding" "binding" {
service_account_id = google_service_account.default.name
role = "roles/iam.workloadIdentityUser"
members = [
"principal://iam.googleapis.com/projects/${data.google_project.project.number}/locations/global/workloadIdentityPools/${local.workload_identity_pool_id}/subject/system:serviceaccount:default:oidc-exp-service-account",
"serviceAccount:${var.gcp_project_id}.svc.id.goog[default/oidc-exp-service-account]",
]
}
Different from the GKE to GCP path, there’s no magic interception of requests. The Kubernetes crafted JWT token will be used to authenticate with the GCP APIs. Therefore, the pod must be configured to both mount the K8s Service Account token and set the CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE environment variable to a JSON file that informs the GCP SDK how to use it and what service account to impersonate. Normally, this JSON can be constructed using the gcloud iam workload-identity-pools create-cred-config command. However, since the structure is static, we can simply define it ahead of time as a ConfigMap:
apiVersion: v1
data:
credential-configuration.json: |-
{
"type": "external_account",
"audience": "//iam.googleapis.com/projects/$GCP_PROJECT_NUMBER/locations/global/workloadIdentityPools/oidc-exp-workload-identity-pool/providers/trusted-eks-cluster",
"subject_token_type": "urn:ietf:params:oauth:token-type:jwt",
"token_url": "https://sts.googleapis.com/v1/token",
"credential_source": {
"file": "/var/run/service-account/token",
"format": {
"type": "text"
}
},
"service_account_impersonation_url": "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/oidc-exp-service-account@$GCP_PROJECT_ID.iam.gserviceaccount.com:generateAccessToken"
}
kind: ConfigMap
metadata:
name: oidc-exp-config-map
namespace: default
And the Pod:
apiVersion: v1
kind: Pod
metadata:
name: gcloud-cli
namespace: default
spec:
containers:
- name: gcloud-cli
image: gcr.io/google.com/cloudsdktool/google-cloud-cli:alpine
command:
- /bin/bash
- -c
- "sleep 1800"
volumeMounts:
- name: token
mountPath: "/var/run/service-account"
readOnly: true
- name: workload-identity-credential-configuration
mountPath: "/var/run/secrets/tokens/gcp-ksa"
readOnly: true
env:
- name: CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE
value: "/var/run/secrets/tokens/gcp-ksa/credential-configuration.json"
serviceAccountName: oidc-exp-service-account
volumes:
- name: token
projected:
sources:
- serviceAccountToken:
audience: https://iam.googleapis.com/projects/$GCP_PROJECT_NUMBER/locations/global/workloadIdentityPools/oidc-exp-workload-identity-pool/providers/trusted-eks-cluster
expirationSeconds: 3600
path: token
- name: workload-identity-credential-configuration
configMap:
name: oidc-exp-config-map
And without any further configuration, the pod can access the GCS bucket:
$ kubectl --context aws exec -it gcloud-cli -- bash
gcloud-cli:/# gcloud storage ls gs://oidc-exp-gcs-bucket
gs://oidc-exp-gcs-bucket/test.txt
Success! 4/4 complete of the scenarios have been successful!
Appendix 1 - GKE to GCP as a vanilla OIDC Provider
While the above example for GKE to GCP is the recommended way to access GCP resources from Kubernetes, after seeing how the EKS to GCP access is done, one is left wondering if we can bypass the magic interception of requests altogether! In fact, that is definitely possible and actually results in an implementation that is even more consistent across the two clouds.
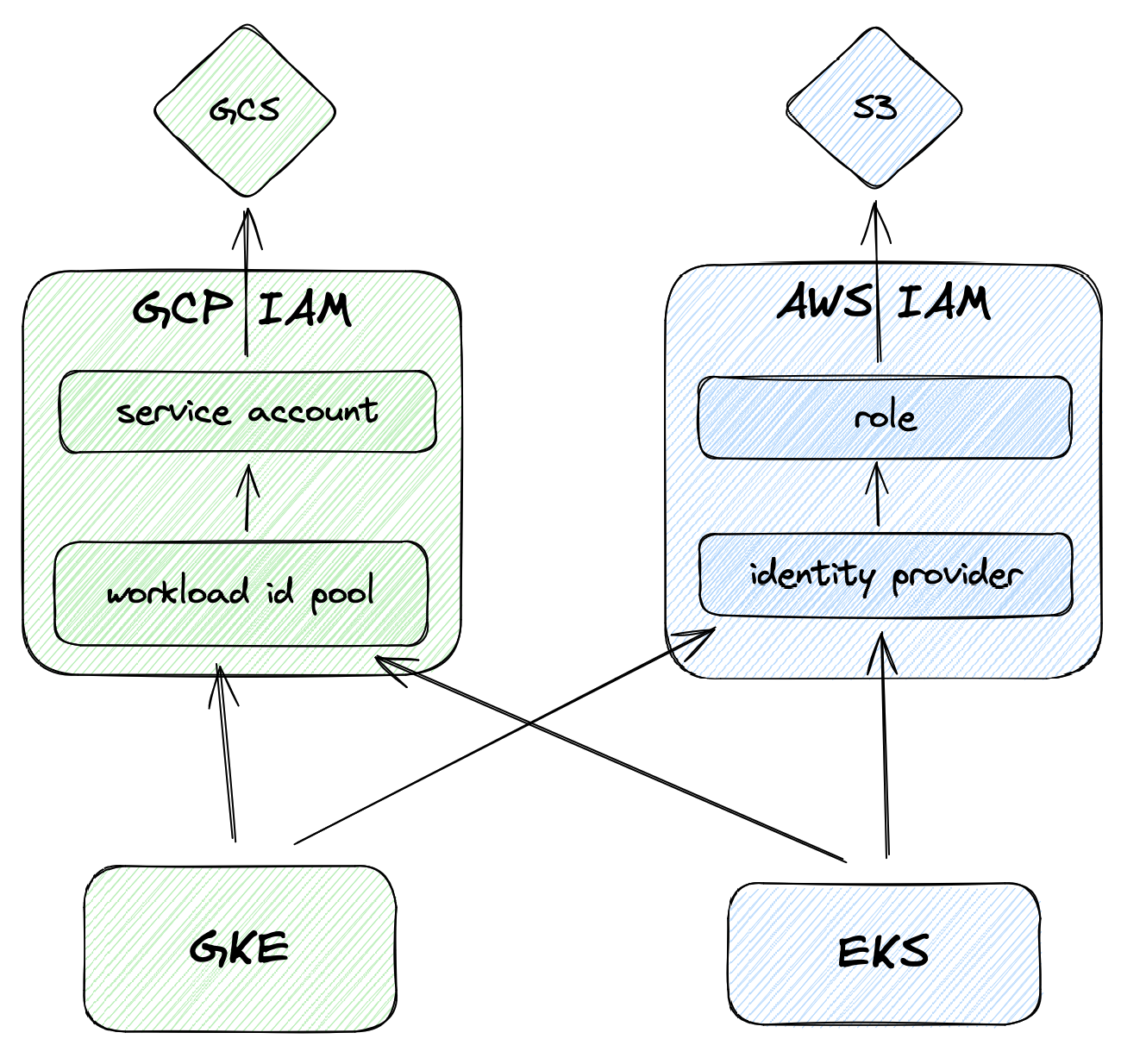
The first step is to remove the workload_identity_config and workload_metadata_config configurations from the GKE Cluster and Node Pool configurations in Terraform. Then, a new google_iam_workload_identity_pool_provider resource for the GKE cluster must be created:
resource "google_iam_workload_identity_pool_provider" "trusted_gke_cluster" {
workload_identity_pool_id = google_iam_workload_identity_pool.pool.workload_identity_pool_id
workload_identity_pool_provider_id = "trusted-gke-cluster"
attribute_mapping = {
"google.subject" = "assertion.sub"
}
oidc {
issuer_uri = local.gke_issuer_url
}
}
Since we aren’t relying on GCP’s magic, we can also remove the GKE annotation from the K8s service account:
apiVersion: v1
kind: ServiceAccount
metadata:
name: oidc-exp-service-account
namespace: default
Finally, the Pod spec for gcloud-cli becomes identical to the EKS one, which requires the creation of the ConfigMap.