Scraping simples e fácil em Python
Nesse post, vamos ver como é fácil realizar um scraping básico de um site. Scraping é a atividade de extrair em um ou mais sites informações de forma automatizada. Geralmente fazemos isso quando queremos dados que não são disponibilizados através de APIs.
A intenção desse post é mostrar como é fácil buscar e armazenar esse tipo de informação. Iremos utilizar Python para essa tarefa, com ajuda de três ferramentas: requests, lxml e dataset. Vamos ver o papel que cada uma desempenha em breve.
O site alvo é o Prog Archives. É um site sobre Rock Progressivo com uma comunidade ativa e que indexa vários gêneros, bandas e álbuns, com notas e comentários. Apesar de fazer um ótimo trabalho em catalogar essas informações, ele não disponibiliza esses dados de forma estruturada através de dumps ou APIs.
O Prog Archives tem um mecanismo de busca bem robusto que permite, entre outras coisas, pesquisar os melhores álbuns de cada ano. Essa será a informação que iremos varrer do site e guardar num banco de dados. Falando em banco de dados, a biblioteca dataset é uma ORM para pessoas preguiçosas (no nosso caso, pessoas que querem um resultado muito rápido), uma vez que você não precisa definir o schema das suas tabelas antes de começar a inserir dados.
O primeiro passo, portanto, é configurar a conexão com um banco de dados SQLite e definir uma tabela:
In [1]: import dataset
In [2]: db = dataset.connect('sqlite:///prog.db')
In [3]: albums_table = db['albums']
O próximo passo é utilizar um ano de exemplo para começarmos a varrer o site. Para o ano de 2013, a URL é http://www.progarchives.com/top-prog-albums.asp?syears=2013. Entre no site e confira como a informação para os melhores álbuns está, pelo menos visualmente, organizada. É possível ver que existe uma tabela, com colunas para posição, nota, nome do álbum e artista, e finalmente o gênero. São essas informações que desejamos extrair de maneira programática.
Para alcançar esses objetivos, temos que abrir essa página através do Python, e é aí que entra a biblioteca requests, que é uma alternativa muito mais “digestível” da urllib2. Para abrir uma página é simples:
In [4]: import requests
In [5]: import sys
In [6]: url = "http://www.progarchives.com/top-prog-albums.asp?syears=2013"
In [7]: response = requests.get(url)
In [8]: if response.status_code != 200:
...: sys.exit('Non 200 status code received')
Repare que definimos uma url, realizamos uma requisição do tipo GET e conferimos se a resposta teve um status code 200, caso contrário, saímos do programa. É interessante notar que o objeto do tipo Response retornado pela requisição possui vários atributos que podem ser úteis, aqui estamos utilizando o status_code e o conteúdo da página, o texto puro HTML, reside no text.
Já temos o conteúdo da página em mãos e o banco de dados está pronto para receber os dados, a única coisa que falta é recuperar esses dados estruturados. É aí que entra a biblioteca lxml. Eu gosto de enxergá-la como uma ferramenta para desconstruir o HTML. Imagine-se escrevendo uma página em HTML: você organiza as informações com uma semântica por trás. Títulos ficam em tags do tipo heading (h1, h2, etc.), datas recebem sua própria formatação através de uma classe CSS, conteúdos de uma mesma comunidade são organizados em estruturas iguais (somente o conteúdo muda, como em uma tabela).
Quanto melhor o trabalho de dar semântica a essas informações, mais fácil será organizá-las através de templates, partials e includes e estilizá-las através de CSS. Por outro lado, quanto mais organizado está um markup de HTML mais fácil será desconstruí-lo, uma vez que menos informação será necessária para descrever de maneira única um elemento.
No caso da página dos melhores álbuns para cada ano, já identificamos, pelo menos visualmente, que existe uma tabela que organiza esses álbuns. Se olharmos para o código veremos que de fato é utilizado o elemento table:
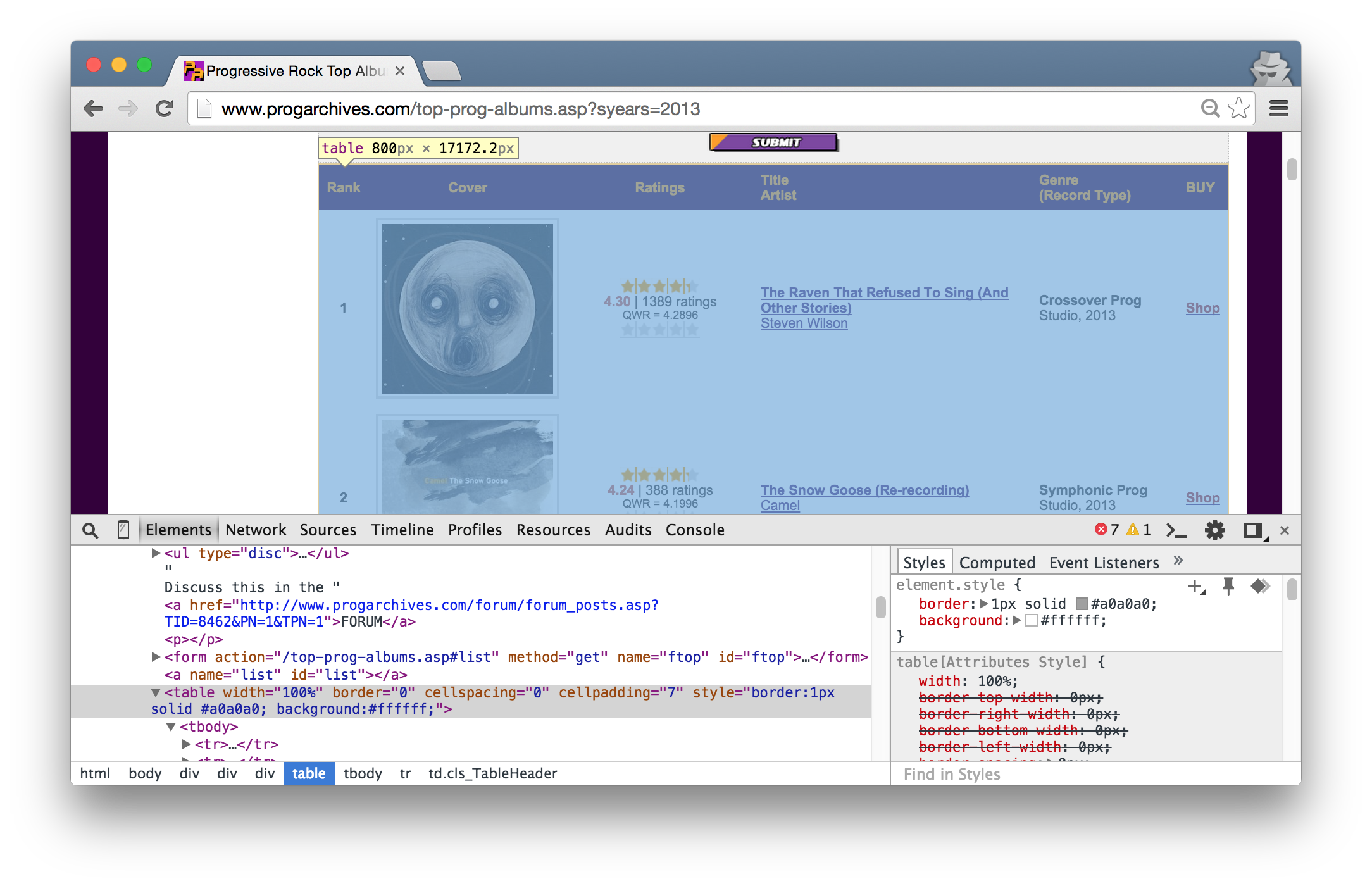
Voltando a ferramenta lxml, a desconstrução é possível de diversas maneiras, incluindo seleção através de CSS Path e XPath. A ideia por trás de ambos é, através da organização e propriedades HTML, descrever unicamente um elemento de um documento. Como mencionado anteriormente, no caso geral, quanto mais organizado e bem construída uma página, menor será a quantidade de informação necessárias para descrever um elemento. Para começarmos o trabalho com o lxml, devemos:
In [9]: from lxml import html
In [10]: parsed = html.fromstring(response.text)
In [11]: parsed
Out[11]: <Element html at 0x102338998>
Em seguida, selecionaremos os elementos de uma maneira exploratória e para isso utilizaremos o XPath. O objetivo aqui não é ensinar XPath (para isso existe esse material), mas sim realizar um scraping rapidamente. Uma das maneiras de enxergar o XPath (e o documento por trás) é como um sistema de arquivos onde você separa os elementos (pastas) por uma /. Todavia, como podem existir vários elementos do mesmo tipo dentre de um elemento pai, todos eles são retornados.
<AAA>
<BBB/>
<CCC/>
<DDD/>
<CCC/>
</AAA>
Ao selecionar /AAA/CCC, os dois elementos CCC são selecionados. Outra propriedade interessante é a capacidade de buscar um elemento que pode ser um descendente com vários nós de distância do elemento atual, para isso utiliza-se o //. Ou seja, o mesmo resultado anterior pode ser atingido através da seleção //CCC. Voltando ao nosso objetivo, sabemos que a informação que desejamos encontra-se em uma tabela, vamos, portanto, pesquisar por esse elemento no documento:
In [12]: parsed.xpath('//table')
Out[12]: [<Element table at 0x10e9399f0>, <Element table at 0x10e939af8>]
Encontramos duas tabelas, vamos inspecionar a primeira delas - vale a pena notar que as tabelas retornadas acima também são do tipo Element, assim como o objeto HTML.
In [13]: list(parsed.xpath('//table')[0])
Out[13]:
[<Element tr at 0x10e939d08>,
<Element tr at 0x10e939e10>,
<Element tr at 0x10e939e68>]
In [14]: parsed.xpath('//table')[0] == parsed.xpath('//table[1]')[0]
Out[14]: True
In [15]: parsed.xpath('//table[1]/tr')
Out[15]:
[<Element tr at 0x10e939d08>,
<Element tr at 0x10e939e10>,
<Element tr at 0x10e939e68>]
Podemos notar acima que podemos manipular os elementos tanto em Python quanto dentro do próprio XPath, além de selecionarmos um de vários descendentes através de índices. Fica claro que a tabela que queremos, a com os álbuns, não pode ser a primeira já que possui somente 3 linhas ou elementos tr. Vejamos a segunda:
In [16]: len(parsed.xpath('//table[2]/tr'))
Out[16]: 100
Aparentemente possui a quantidade de elementos esperada, os 100 melhores álbuns de 2013. Para explorar o conteúdo dessas linhas:
In [17]: parsed.xpath('//table[2]/tr[1]/*')
Out[17]:
[<Element td at 0x10e960b50>,
<Element td at 0x10e960ba8>,
<Element td at 0x10e960c00>,
<Element td at 0x10e960c58>,
<Element td at 0x10e960cb0>,
<Element td at 0x10e960d08>]
Exatamente as seis colunas que encontramos na página. E se inspecionarmos todos os elementos filhos dessa linha primeira linha, recuperando o seu conteúdo de texto:
In [18]: parsed.xpath('//table[2]/tr[1]//*/text()')
Out[18]:
['1',
'\r\n\r\n',
'\r\n',
"\r\ngenerateReadOnlyStarbox('readOnlyRating_1_39840', 4.30155979202773);\r\n",
'\r\n\r\n',
'4.30',
' | ',
'1389',
' ratings\r\n\r\n',
'QWR = 4.2896',
'\r\n\r\n',
'\r\n',
"\r\ngenerateQuickRatingStarbox('quickRating_1_39840', 0, '-1');\r\n",
'\r\n\r\n',
'The Raven That Refused To Sing (And Other Stories)',
'Steven Wilson',
'Crossover Prog',
'Studio, 2013',
'Shop']
Bingo! Conseguimos recuperar a informação que buscávamos e agora é um trabalho de manipulação dos dados. Por exemplo, caso buscássemos os cinco melhores álbuns de 2013, bastaria realizar a seleção correta:
In [19]: parsed.xpath('//table[2]/tr//*[15]/text()')[:5]
Out[19]:
['The Raven That Refused To Sing (And Other Stories)',
'The Snow Goose (Re-recording)',
u'La Crudelt\xe0 Di Aprile',
'Ritual',
'Armenia']
Para finalizar, vamos reunir as informações que desejamos, tendo como exemplo o primeiro álbum:
In [20]: position = int(parsed.xpath('//table[2]/tr[1]//*/text()')[0])
In [21]: rating = float(parsed.xpath('//table[2]/tr[1]//*/text()')[5])
In [22]: title = parsed.xpath('//table[2]/tr[1]//*/text()')[14]
In [23]: artist = parsed.xpath('//table[2]/tr[1]//*/text()')[15]
In [24]: genre = parsed.xpath('//table[2]/tr[1]//*/text()')[16]
In [25]: [position, rating, title, artist, genre]
Out[25]:
['1',
4.3,
'The Raven That Refused To Sing (And Other Stories)',
'Steven Wilson',
'Crossover Prog']
Para inserir no banco de dados, na tabela de álbuns criada é bem simples, já que não temos que criar o arquivo, nem a tabela, tampouco o schema - basta definir um dicionário com os atributos desejados:
In [26]: albums_table.insert(dict(
position=position,
rating=rating,
title=title,
artist=artist,
genre=genre,
year=2014
))
Out[26]: 1
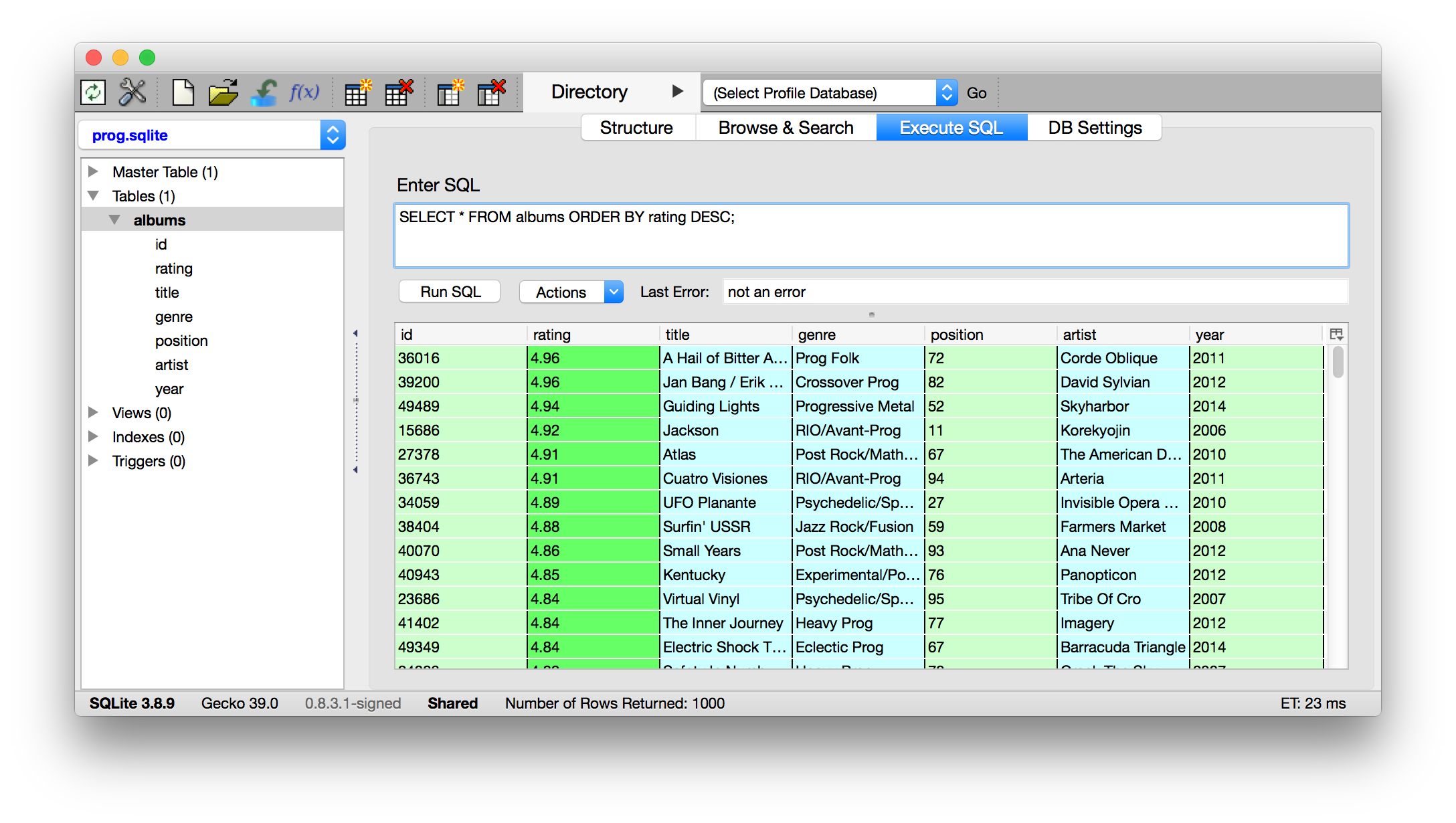
Para o restante da página, basta iterar sobre os elementos tr e inserir as informações. O exemplo completo pode ser encontrado nesse gist. O resultado pode ser ser visualizado na tabela e de agora em diante você pode realizar novas análises e visualizações.
Observação: através do inspetor do Chrome ou Firefox, é possível selecionar o caminho XPath ou CSS de um documento que, na teoria, poderia ser utilizado no lxml. Entretanto, os navegadores tendem a inserir elementos caso esses não existam na página. No caso do nosso exemplo, repare que o Chrome inseriu um elemento tbody que não existia na página.
/html/body/div[1]/div[4]/div[2]/table/tbody/tr[1]
Caso tivéssemos utilizado o caminho do navegador para a primeira linha, não teriámos encontrado nenhum elemento através do lxml.