Beanstalkd: a simple and reliable message queue
Many times you find yourself in a position where you need to pass messages around processes or agents. If you are building a (micro) service-oriented architecture, a message broker or queue becomes a basic building block.
The first option that usually comes to mind is RabbitMQ, which is a great project written in Erlang/OTP with client drivers in dozens of languages. But it is also a pretty big guy for situations where you want a dead simple solution. Other times, you see some folks using Redis as a lightweight solution, but as you soon find out, it was not really created for that purpose, although many people create libraries and wrappers to make it look like so.
I’d like to give beanstalkd the attention it deserves. It is an ultra lightweight message broker written in C, with client drivers in a bunch of languages and a concise API. It also features a brief TXT protocol in plain English, which is very digestible. Running beanstalkd is a make away:
curl -L https://github.com/kr/beanstalkd/archive/v1.10.tar.gz | tar xz
cd beanstalkd-1.10
make
./beanstalkd
The life cycle of a job is very straightforward, and queues in beanstalkd are called tubes:
- Both producers and consumers connect to the beanstalkd server
- The producer
usesa tube - The consumer
watchesthe same tube - The producer
putsa job into the tube - The consumer
reservesa job from the queue - The consumer
deletesthe job
Jobs can be any string, a serialized JSON or XML that makes sense to your application’s universe. Most times, I end up using JSON because they are easily mapped to first class structures on different languages.
An use case
At IDXP, we rely on Ruby’s rich web ecosystem and BDD library RSpec to build our web facing API, but all the data science backed calculations are performed using Python, given its powerful and throughly tested scientific libraries.
On this tutorial, our sample use case will consist of an “expensive” calculation being “requested” in Ruby and “answered” in Python. Our task will be to identify hand written digits using Support Vector Machines, which are already implemented in Python thanks to scikit-learn.
For example, the hand written digit 4 below, can be represented by a 8x8 matrix with numbers ranging from 0 to 15 in a grey scale.
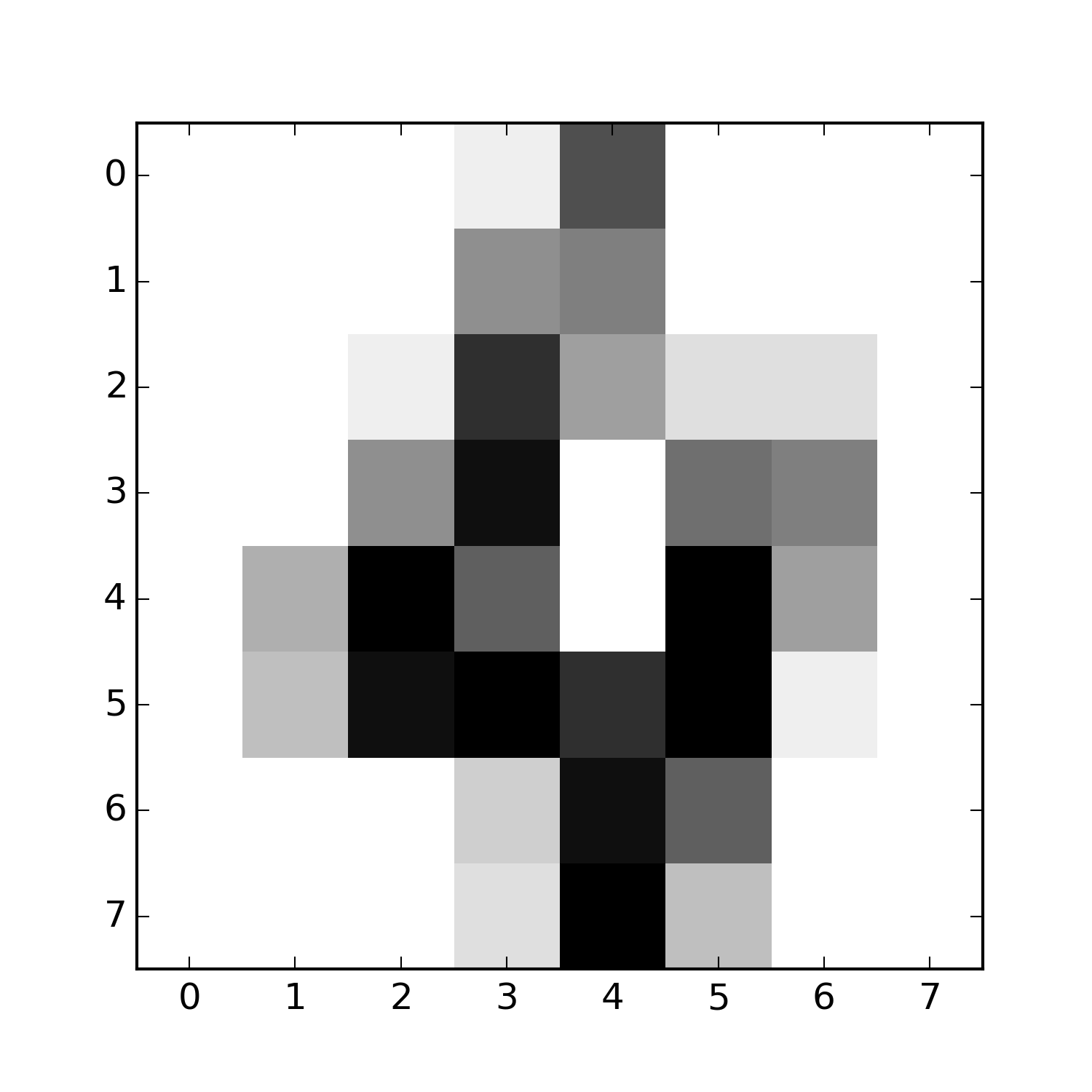
| 0 | 0 | 0 | 1 | 11 | 0 | 0 | 0 |
| 0 | 0 | 0 | 7 | 8 | 0 | 0 | 0 |
| 0 | 0 | 1 | 13 | 6 | 2 | 2 | 0 |
| 0 | 0 | 7 | 15 | 0 | 9 | 8 | 0 |
| 0 | 5 | 16 | 10 | 0 | 16 | 6 | 0 |
| 0 | 4 | 15 | 16 | 13 | 16 | 1 | 0 |
| 0 | 0 | 0 | 3 | 15 | 10 | 0 | 0 |
| 0 | 0 | 0 | 2 | 16 | 4 | 0 | 0 |
Given a large enough sample of those hand written images and matrices, with their corresponding intended value, we can use this information to train a SVM model that can be used to identify new images. Such dataset exists and is part of the scikit-learn datasets. In our use case, these new images will be scanned in Ruby, maybe because we want it as part of a Rails application.
Here’s the Python code. Notice how we are using all but the last digit on the training set to fit our classifier. This last “image” will be manually sent from ruby.
# replier.py
from beanstalkc import Connection
from sklearn import svm, datasets
from json import loads
def configure_beanstalk():
beanstalk = Connection() # connecting to beanstalk
beanstalk.watch('question') # tube to watch for jobs
beanstalk.use('answer') # tube to post jobs
return beanstalk
def prepare_classifier():
digits = datasets.load_digits()
classifier = svm.SVC(gamma=0.001, C=100.0)
classifier.fit(digits.data[:-1], digits.target[:-1])
return classifier
if __name__ == '__main__':
beanstalk = configure_beanstalk()
classifier = prepare_classifier()
while True:
job = beanstalk.reserve() # reserve job from watched tubes
matrix = loads(job.body) # get job content
digit = int(classifier.predict(matrix)[0])
beanstalk.put(str(digit)) # enqueue a job on the used tube
job.delete() # deleting job since it was sucessful
And here is the Ruby code:
# digit_inquisition.rb
require 'beaneater'
require 'json'
class DigitInquisition
def initialize
@beanstalk = Beaneater.new 'localhost:11300'
@question_tube = beanstalk.tubes['question']
@answer_tube = beanstalk.tubes['answer']
end
attr_reader :beanstalk, :question_tube, :answer_tube
def ask
question_tube.put(digit_image.to_json)
job = answer_tube.reserve
puts "==> The requested digit is #{job.body}"
job.delete
end
private
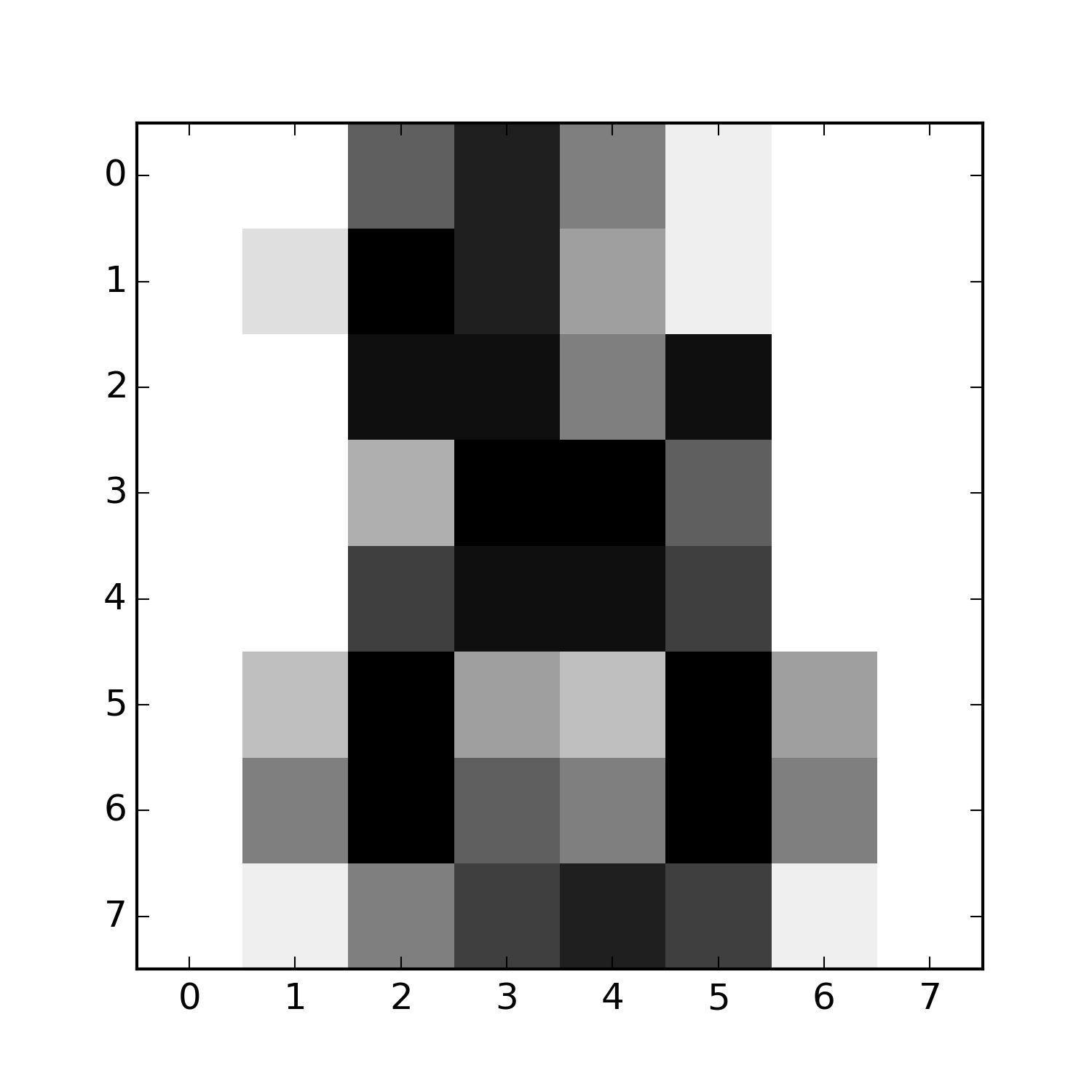
def digit_image
[0, 0, 10, 14, 8, 1, 0, 0,
0, 2, 16, 14, 6, 1, 0, 0,
0, 0, 15, 15, 8, 15, 0, 0,
0, 0, 5, 16, 16, 10, 0, 0,
0, 0, 12, 15, 15, 12, 0, 0,
0, 4, 16, 6, 4, 16, 6, 0,
0, 8, 16, 10, 8, 16, 8, 0,
0, 1, 8, 12, 14, 12, 1, 0]
end
end
DigitInquisition.new.ask
To run both programs, first leave beanstalkd running on the background, then the python script. Finally, run the ruby script to get the answer from the last image of the digit dataset:
$ beanstalkd &
$ python replier.py &
$ ruby digit_inquisition.rb
==> The requested digit is 8
Extra configuration parameters
Beanstalkd jobs reside in memory and are not persisted by default, so any pending jobs are lost if you shut it down. To turn persistance on, use the -b flag:
beanstalkd -b /var/lib/beanstalkd
Another useful flag is -z which lets you choose the maximum job size in BYTES. And, of course, -h:
Use: beanstalkd [OPTIONS]
Options:
-b DIR wal directory
-f MS fsync at most once every MS milliseconds (use -f0 for "always fsync")
-F never fsync (default)
-l ADDR listen on address (default is 0.0.0.0)
-p PORT listen on port (default is 11300)
-u USER become user and group
-z BYTES set the maximum job size in bytes (default is 65535)
-s BYTES set the size of each wal file (default is 10485760)
(will be rounded up to a multiple of 512 bytes)
-c compact the binlog (default)
-n do not compact the binlog
-v show version information
-V increase verbosity
-h show this help
Conclusion
The first time I used beanstalkd was in 2011, during my brief work at DeskMetrics where it was used to process hundreds of data points every second. Since then, it became an integral part of my toolset, having used it on Como nos Sentimos to pass tweets around processes of sentiment identification and geolocation, and as I’ve mentioned, at IDXP. I haven’t seen it hang up or crash a single time, only a stable API throughout the last five years.